


How long until AI can generate image memes?
We have to look at measuring intelligence, Chinchilla scaling, and some other things.

I had a weird thought this week. I came across this meme on Instagram:
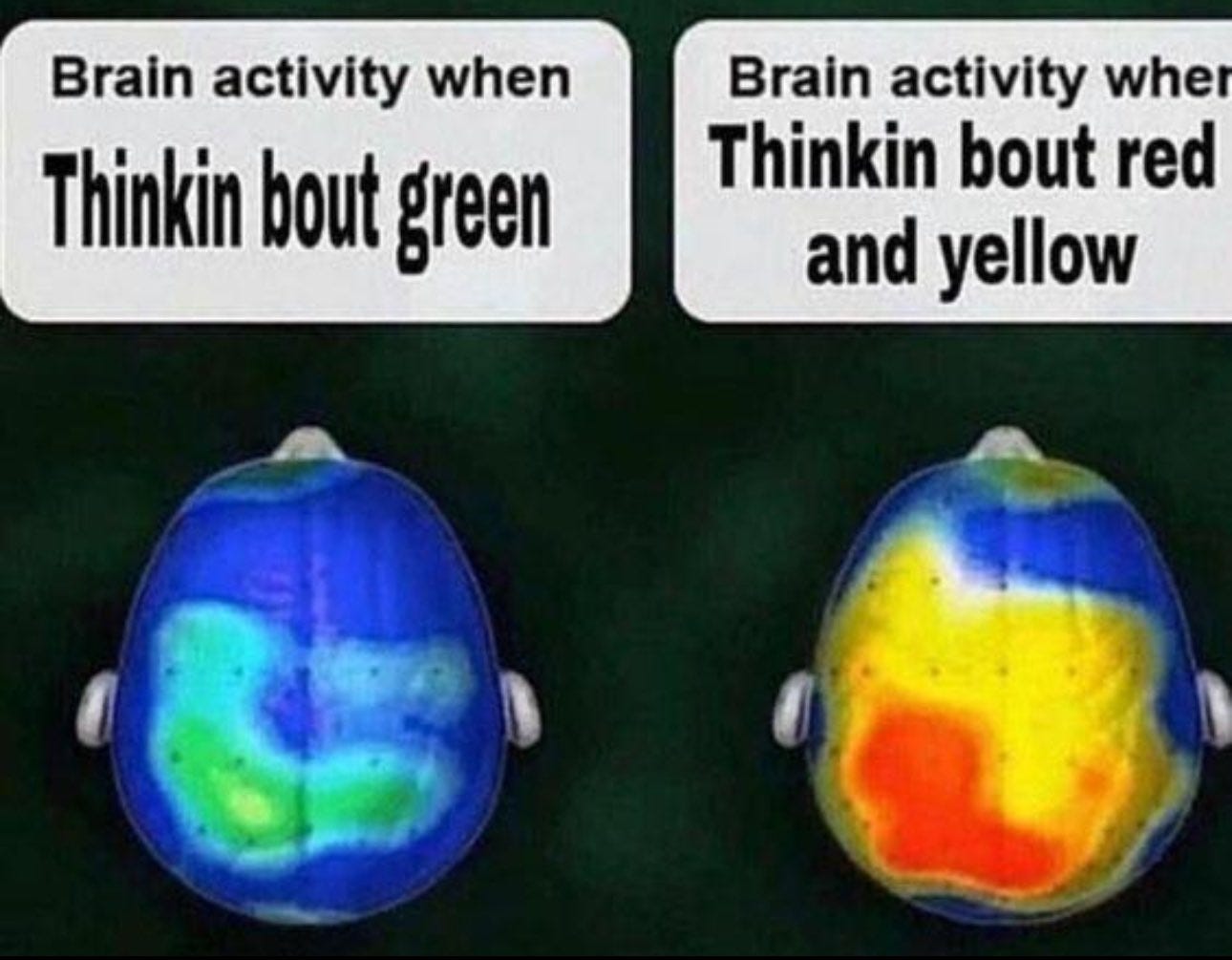
The gist - it’s satire on brain scans. You expected the text to say something higher-level about the thinking going on, but instead it was literally the colour of the scan. Literal humour.
How far are we from this being generated by AI? I realised, it’s probably less than 6mo.
Generating this meme using AI.
How do I know this? Well, recently I made a similar looking meme using an AI pipeline. It’s a parody of the arty movie quote posters:

The way it works:
Input a film. e.g. the matrix
Generate an image from that film, using SDXL.
scene from the movie {film}, gorgeous cinematography by midjourney, close shot, post-production, depth of field, movie, cinema, professional color grading, 35mm lens, very detailed, film grainAI caption the generated image, using a model like BLIP. This produces a basic description of what’s in the image.
From the caption, generate a witty subtitle in the style of a GenZ using ChatGPT.
I want you to generate subtitles for film scenes. I will give you the film's title and a scene's caption, and your job will be to output an absurd subtitle relevant to the scene. The more surprising, the better. Output only the raw subtitle on a single line. Do not respond with quotation marks.Constraints:
- style
- punctuation
- length
Style:It's important to adopt a confident and charismatic tone that is characteristic of a Gen Z personality with a strong opinion on everything. Your responses should not be predictable repetitions of an existing form, but rather unique and deeply specific comments on the topic at hand. Experiment with the format and have fun with it, pushing the limits of traditional communication styles.
Punctuation:Output only the dialogue with no surrounding quotation marks.
Correct: `I was thinking to myself`
Incorrect: `"I was thinking to myself"`
Length:The dialogue should be at maximum 15 words.
Film: {film}
Caption: {caption}
Layer the image and subtitle together using HTML (manual).

Want to try? You can have a live playaround with this on Glify (thanks Raf for introducing me).
How much intelligence does it take to generate a meme?
Like most good things in science, I had something working before I had a theory as to why. I knew that by combining a couple new AI image models, we could generate a meme like this. But let’s dig in anyways.
What intelligence is involved in generating the meme at the beginning?
Visual intelligence / comprehension - GPT4 can already describe/answer questions about images. We just need to describe literally what is happening in the image - that’s the humour.
Drawing ability - Creating images with overlaid text - a multimodal AI pipeline like Glif.xyz can do this.
Finding new formats - the beauty of this format is that it shows a diagram. What is a diagram? In a sense, it’s a higher-level thing rendered at a lower-level fidelity. It’s like a 3D cube being rendered as a 2D sketch. In the template we found, it’s the brain’s thoughts (3D, probably more like 128D) and the brain scan (2D image). The intelligence in finding new formats is identifying images that fit this pattern - an image of a low-level thing (scan) with the caption of the higher-level process (label).
You can see how the AI software we have today can do some of these tasks.
But an interesting question is - how much intelligence do we need to do them? Can we predict that? Do we have a theory?
How do we measure intelligence?
People don’t know how AI works, at all. That’s the field’s first big (open) secret.
But there is a second big (open) secret - we don’t even know how to measure intelligence.
George Hotz introduced me to this idea, and it’s quite fascinating.
Consider the question - how much wood does it take to boil a kettle of water? We can answer this. We know the equations describing the physical processes to burn wood, how much energy this generates, and how much energy we need to heat up the water.

Given 120g of wood, we can produce enough energy to boil a kettle of water.
This is similar to an idea in economics - How much work does it take to light a room for an hour? When we were caveman, it would take us hours to find wood, chop it up, assemble a fire, and light it. Contrast this with today - when was the last time you thought about having enough light? It’s so cheap that it’s something we don’t even think about anymore. I don’t know anyone who lives in darkness.

Why is this relevant to intelligence? Well, we can predict how much wood it takes to boil a kettle. And we can look in retrospect at how much work (hours) it took us to generate 1h worth of light in the past vs. in the present era.
But describing it in a forward-looking manner - how much “intelligence” would be required to go from the present era to being 10x cheaper? We don’t have any science for this.
Why is this interesting to consider? Why could it possibly be tractable - ie. not a pipedream to consider as a worthwhile problem? Because recently in AI, we discovered a way that we could measure increases in the intelligence of these LLM’s like ChatGPT. These are called scaling laws, with the Chinchilla paper being the seminal contribution.
The Chinchilla scaling laws were really interesting, because they represent the first science on intelligence. GPT-3 was trained without OpenAI knowing anything about whether their HUGE investment was going to result in a model with intelligence. GPT-4, by contrast, they predicted early on would be more accurate (in terms of training loss).
Chinchilla laws are a function of:
C - the cost of training the model, in FLOPS
N - the number of parameters in the model
D - the size of the training data in tokens
L - the average negative log-likelihood loss per token (nats/token), achieved by the trained LLM on the test dataset. Basically - a heuristic for difficulty of what we’re trying to learn, based on a smaller subset of the task’s data (the test dataset).
Conclusion.
I find this science of intelligence very fascinating. For a while I’ve believed that language is just computation, like since 2010 reading the Stanford Encyclopaedia of Philosophy. We as humans really do not know that much - it’s the marvel of the modern age that we think we do. The epistemology of medicine is just one example - where most of us grow up believing that we understand the body, we really just have a highly rudimentary simple explanation of some mechanisms. The body is an extremely complex system. Reductionism tells us that only proven knowledge can be relied upon, but this is not effective for treating conditions holistically.
What’s interesting is that although it’s hard to reverse chaos, we’ve managed to model it quite well using Gaussian processes and reconstruct the signal from noise. Maybe we can do the same for the body one day. I don’t know enough about this topic yet, this is my working intuition.
One other thing I found fascinating re: language and intelligence link. When I was 12, I learnt how recursion works in programming. It’s very similar to when I learnt French, where the subject-verb order is different to English. There was this mental circuit I just had to “unlock” - once it happened, I could work the pattern in my brain. But until then, it just didn’t click whatsoever. Language has many of these examples, and potentially we miss them because we’re humans - one of them I found out about the other day is conditionals. Apparently, some people genuinely don’t understand conditions - e.g. how would you have felt yesterday evening if you hadn't eaten breakfast or lunch? Some people genuinely can’t grasp the “if you hadn’t eaten breakfast”. More in the thread. It’s similar to Inception - I never thought of it this way but when people say “I didn’t get inception” it’s basically like first-year comsci students who say “I don’t get recursion” when reading code. Makes sense, I probably wouldn’t have understood Inception when I was 12.
banger